Topics use the Apache Kafka protocols for producing data for (input) and consuming data from (output) a VoltDB database. The configuration file declares the topic and specifies the stored procedure that receives the inbound data. You can use a database table or stream — or even a stream view — as the source for topic output. The CREATE... EXPORT TO TOPIC statement identifies the stream or table that is used to queue outbound data to the specified topic. VoltDB topics operate just like Kafka topics, with the database nodes acting as Kafka brokers. However, unlike Kafka, VoltDB topics also have the ability to analyze, act on, or even modify the data as it passes through.
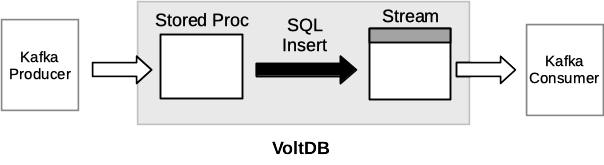
As the preceding diagram shows, data submitted to the topic from a Kafka producer (either using the Kafka API or using a tool such as Kafka Connect) is passed to the stored procedure, which then interprets and operates on the data before passing it along to the stream or table through standard SQL INSERT semantics. Note that the named procedure must exist before input is accepted. Similarly, the stream or table must be declared using the EXPORT TO TOPIC clause and the topic be defined in the configuration file before any output is queued. So, it is a combination of the database schema and configuration file that establishes the complete topic workflow.
For example, the following SQL statements declare the necessary stored procedure and stream and the configuration file defines a topic eventLogs that integrates them:
- Schema DDL
CREATE STREAM eventlog PARTITION ON COLUMN e_type EXPORT TO TOPIC eventlogs ( e_type INTEGER NOT NULL, e_time TIMESTAMP NOT NULL, e_msg VARCHAR(256) ); CREATE PROCEDURE PARTITION ON TABLE eventlog COLUMN e_type FROM CLASS mycompany.myprocs.checkEvent;- Configuration File
<topics> <topic name="eventLogs" procedure="checkEvent"/> </topics>
Concerning Case Sensitivity
The names of Kafka topics are case sensitive. That means that the name of the topic matches exactly how it is specified in the configuration file. So in the previous example, the topic name eventLogs is all lowercase except for the letter "L". This is how the producers and consumers must specify the topic name. But SQL names — such as table and column names — are case insensitive. As a result, the topic name specified in the EXPORT TO TOPIC clause does not have to match exactly. In other words, the topic "eventLogs" matches any stream or table that specifies the topic name with the same spelling, regardless of case.
The structure of a topic message — that is, the fields included in the message and the message key — is
defined in the schema using the EXPORT TO TOPIC... WITH clause. Other characteristics of how the message is handled, such as
the data format, security, and retention policy, are controlled by <property> tags
in the configuration file. The following sections discuss:
Understanding the different types of topics
Declaring VoltDB topics
Configuring and managing topics
Configuring the topic server
Calling topics from external consumers and producers
Using opaque topics
VoltDB supports four different types of topics, depending on how the topic is declared:
A fully processed topic is a pipeline that supports both input and output and passes through a stored procedure. This is defined using both the
procedureattribute in the configuration file and the EXPORT TO TOPIC clause in the CREATE statement.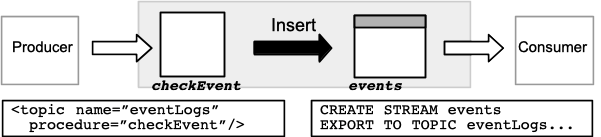
An input-only topic only provides for input from Kafka producers. You define an input-only topic by specifying the
procedureattribute, without any stream or table including a corresponding EXPORT TO TOPIC clause.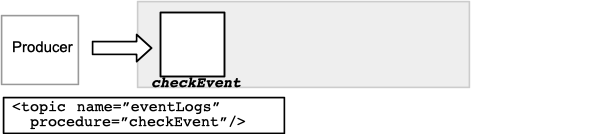
An output-only topic only provides for output to Kafka consumers but can be written to by VoltDB INSERT statements. You define an output-only topic by including the EXPORT TO TOPIC clause, but not specifying a procedure in the topic declaration.
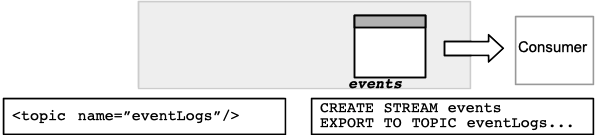
An opaque topic supports input and output but provides for no processing or interpretation. You define an opaque topic using the
opaque="true"attribute in the configuration file, as described in Section 15.6.6, “Using Opaque Topics”.
You declare and configure topics by combining SQL stored procedures and streams or tables with topic declarations in
the database configuration file. The topic itself is defined in the configuration file, using the <topics> and <topic> elements. The configuration
also lets you identify the stored procedure used for input from producers:
<topics>
<topic name="eventLogs"
procedure="eventWatch"/>
</topics>For output, you include the EXPORT TO TOPIC clause when you declare a stream or table. Once the schema object includes the EXPORT TO TOPIC clause and the topic is defined in the configuration file, any records written into the stream or table are made available to consumers through the topic port.
You can control what parts of the records are sent to the topic, using the WITH KEY/VALUE clauses. The WITH VALUE clause specifies which columns of the object are included in the body of the topic message and their order. The WITH KEY clause lets you specify one or more columns as a key for the message. Columns can appear in either the message body or the key, in both, or in neither, as needed. In all cases, the lists of columns are enclosed in parentheses and separated by commas.
So, for example, the following stream declaration associates the stream events with the topic eventLogs and selects two columns for the body of the topic message and one column as the key:
CREATE STREAM events
PARTITION ON COLUMN event_type
EXPORT TO TOPIC eventLogs
WITH KEY (event_type) VALUE (when,what)
( event_type INTEGER NOT NULL,
when TIMESTAMP NOT NULL,
what VARCHAR(256)
);Since VoltDB does not control what content producers send to the topic, it cannot dictate what columns or datatypes the stored procedure will receive. Instead, VoltDB interprets the content from its format. By default, text data is interpreted as comma-separated values. All other data is interpreted as a single value based on the data itself. On the other hand, if the topic is configured as using either JSON or AVRO formatted data in the configuration file, the incoming data from producers will be interpreted in the specified format.
Any errors during the decoding of the input fields is recorded in the log file. If the input can be decoded, the message fields are used, in order, as arguments to the store procedure call.
Only one key field is allowed for input. By default, the key is not passed to the specified stored procedure; only
the message fields of the topic are passed as parameters to the stored procedure. If you want to include the key in the
list of parameters to the stored procedure, you can set the property
producer.parameters.includeKey to true and the key will be included as the partitioning
parameter for the procedure. For example:
<topics>
<topic name="eventLogs" procedure="eventWatch">
<property name="producer.parameters.includeKey">true</property>
</topic>
</topics>Declaring the topic and its schema object and/or procedure are the only required elements for creating a topic. However, there are several other attributes you can specify either as part of the declaration or as clauses to the stored procedure and stream or table declarations. Those attributes include:
Permissions — Controlling access to the topic by consumers and producers
Retention — Managing how long data is retained in the topic queue before being deleted
Data Format — Choosing a format for the data passed to the external clients
When security is enabled for the database, the external clients must authenticate using a username and password when they initiate contact with the server. Access to the topic is handled separately for consumers and producers.
For producers, access to the topic is controlled by the security permissions of the associated stored procedure, as defined by the CREATE PROCEDURE... ALLOW clause or the generic permissions of the user account's role. (For example, a role with the ALLPROC or ADMIN permissions can write to any topic.)
For consumers, access to the topic is restricted by the allow attribute of
the topic declaration in the configuration file. If allow is not specified, any
authenticated user can read from the topic. If allow is included in the
declaration, only users with the specified role(s) have access. You specify permissions by providing a comma-separated
list of roles that can read from the topic. For example, the following declaration allows users with the
kreader and operator roles to read from the topic
eventLogs:
<topics>
<topic name="eventLogs" allow="kreader,operator"/>
</topics>Unlike export or import, where there is a single destination or source, topics can have multiple consumers and producers. So there is no specific event when the data transfer is complete and can be discarded. Instead, you must set a retention policy that defines when data is aged out of the topic queues. You specify the retention policy in terms of either the length of time the data is in queue or the volume of data in the queue.
For example, if you specify a retention policy of five days, after a record has been in the queue for five days, it will be deleted. If, instead, you set a retention policy of five gigabytes, as soon as the volume of data in the queue exceeds 5GB, data will deleted until the queue size is under the specified limit. In both cases, data aging is a first in, first out process.
You specify the retention policy in the retention attribute of the <topic> declaration. The retention value is a positive integer and a unit, such as "gb"
for gigabytes or "dy" for days. The following is the list of valid retention units:
- Time
mn — Minutes hr — Hours dy — Days wk — Weeks mo — Months yr — Years - Size
mb — Megabytes gb — Gigabytes
If you do not specify a retention value, the default policy is seven days (7 dy).
VoltDB topics are composed of three elements: a timestamp, a record with one or more fields, and an optional set of keys values. The timestamp is generated automatically when the record is inserted into the stream or table. The format of the record and the key depends on the data itself. Or you can specify a format for the record, for the key, or for both using properties of the topic declaration in the configuration file.
For single value records and keys, the data is sent in the native Kafka binary format for that datatype. For multi-value records or keys, VoltDB defaults to sending the content as comma-separated values (CSV) in a text string. Similarly, on input from producers, the topic record is interpreted as a single binary format value or a CSV string, depending on the datatype of the content.
You can control what format is used to send and receive the topic data using either the format attribute of the <topic> element, or
separate <property> child elements to select the format of individual
components. For example, to specify the format for the message and the keys for both input and output, you can use the
attribute format="avro":
<topics>
<topic name="eventLogs" format="avro"/>
</topics>To specify individual formats for input versus output, or message versus keys, you can use <property> elements as children of the <topic>
tag, where the property name is either consumer or producer followed by
format and, optionally, the component type — all separated by periods. For example, the
following declaration specifies Avro for both consumers and producers, and is equivalent to the preceding example using
the format attribute:
<topics>
<topic name="eventLogs">
<property name="consumer.format">avro</property>
<property name="producer.format">avro</property>
</topic>
</topics>The following are the valid formatting properties:
consumer.formatconsumer.format.keyconsumer.format.valueproducer.format.value
For input, note that you cannot specify the format of the key. This is because only a single key value is supported for producers and it is always assumed to be in native binary or string format.
Depending on what format you choose, you can also control specific aspects of how data is represented in that format. For example, you can specify special characters such as the separator, quote, and escape character in CSV format. Table 15.10, “Topic Formatting Properties” lists all of the supported formatting properties you can use when declaring topics in the configuration file.
Table 15.10. Topic Formatting Properties
| Property | Values | Description |
|---|---|---|
| consumer.format | avro, csv, json | Format of keys and values sent to consumers. Supersedes the format definition in the <topic> deployment element. The default is CSV. |
| consumer.format.value | avro, csv, json | Format of values sent to consumers. Supersedes the format definition in the <topic> deployment element and the "consumer.format" property. The default is CSV. |
| consumer.format.key | avro, csv, json | Format of keys sent to consumers. Supersedes the format definition in the <topic> deployment element and the "consumer.format" property. The default is CSV. |
| producer.format.value | avro, csv, json | Format of values received from producers. Supersedes the format definition in the <topic> deployment element. The default is CSV. |
| config.avro.timestamp | microseconds, milliseconds | Unit of measure for timestamps in AVRO formatted fields. The default is microseconds. |
| config.avro.geographyPoint | binary, fixed_binary, string | Datatype for GEOGRAPHY_POINT columns in AVRO formatted fields. The default is fixed_binary. |
| config.avro.geography | binary,string | Datatype for GEOGRAPHY columns in AVRO formatted fields. The default is binary. |
| config.csv.escape | character | Character used to escape the next character in a quoted string in CSV format. The default is the backslash "\". |
| config.csv.null | character(s) | Character(s) representing a null value in CSV format. The default is "\N". |
| config.csv.quote | character | Character used to enclose quoted strings in CSV format. The default is the double quotation character ("). |
| config.csv.separator | character | Character separating values in CSV format. The default is the comma ",". |
| config.csv.quoteAll | true, false | Whether all string values are quoted or only strings with special characters (such as commas, line breaks, and quotation marks) in CSV format. The default is false. |
| config.csv.strictQuotes | true, false | Whether all string values are expected to be quoted on input. If true, any characters outside of quotation marks in text fields are ignored. The default is false. |
| config.csv.ignoreLeadingWhitespace | true, false | Whether leading spaces are included in string values in CSV format. The default is true. |
| config.json.schema | embedded, none | Whether the JSON representation contains a property named "schema" embedded within it or not. If embedded, the schema property describes the layout of the object. The default is none. |
| config.json.consumer.attributes | string | Specifies the names of outgoing JSON elements. By default, JSON elements are named after the table columns they represent. This property lets you rename the columns on output. |
| config.json.producer.attributes | string | Specifies the name and order of the JSON elements that are inserted as parameters to the topic input procedure. |
| producer.parameters.includeKey | true, false | Whether the topic key is included as the partitioning parameter to the stored procedure call. The default is false. |
| opaque.partitioned | true, false | Whether the opaque topic is partitioned. Ignored if not an opaque topic. The default is false |
| topic.store.encoded | true, false | Whether the topic is stored in the same format as issued by the producer: optimizes transcoding to consumers when producer and consumer formats are identical. The default is false. |
When using AVRO format, you must also have access to an AVRO schema registry, which is where VoltDB stores the schema for AVRO-formatted topics. The URL for the registry is specified in the database configuration file, as described in the next section.
Communication between the VoltDB database and topic clients is handled by a separate server process: the topic
server. The topic server process is started whenever VoltDB starts with the <topics> element declared and enabled in the configuration file.
By default, the topic server, when running, listens on port 9092. You can specify a different port with the
--topicsport flag when you start the server with the voltdb start command. Other
aspects of the topic server operation are configured as properties of the <broker> element, which if present must be the first child of the <topics> element. The following are the supported properties of the <broker>
element:
cluster.idgroup.initial.rebalance.delay.msgroup.load.max.sizegroup.max.session.timeout.msgroup.max.sizegroup.min.session.timeout.mslog.cleaner.dedupe.buffer.sizelog.cleaner.delete.retention.mslog.cleaner.threadsnetwork.thread.countoffsets.retention.check.interval.msoffsets.retention.minutesquota.throttle.max_msquota.request.bytes_per_secondquota.request.processing_percentquota.response.bytes_per_secondretention.policy.threads
For example, this declaration configures the broker using a cluster ID of 3 and five network threads:
<topics>
<broker>
<property name="cluster.id">3</property>
<property name="network.thread.count">5</property>
</broker>
</topics>Finally, you can additionally tune the performance of the topic server by adjusting the threads that manage the
inbound and outbound connections. You can specify a threadpool for the topic server to use for processing client requests
using the threadpool attribute of the <topics>, then specify a size for the pool in the <threadpools> element:
<topics threadpool="topics"> [ . . . ] </topics> <threadpools> <pool name="topics" size="10"/> </threadpools>
Once the topic has been declared in the database configuration and the appropriate streams, tables, and stored procedures created in the schema, the topic is ready for use by external clients. Since VoltDB topics use the Kafka API protocol, any Kafka consumer or producer with the appropriate permissions can access the topics. For example, you can use the console consumer that comes with Kakfa to read topics from VoltDB:
$ bin/kafka-console-consumer.sh --from-beginning \ --topic eventLogs --bootstrap-server myvoltdb:9092
You can even use the console producer. However, whether using an existing producer or creating your own, you must
explicitly disable idempotency or else VoltDB will not accept data from your application. You disable idempotency by
setting the Kafka property enable.idempotence to "false".
To optimize write operations, Kafka also needs to know the VoltDB partitioning scheme. So it is strongly recommended
that you define the Kafka ProducerConfig.PARTITIONER_CLASS_CONFIG property to point to the VoltDB
partitioner for Kafka. By defining the PARTITIONER_CLASS_CONFIG, VoltDB can ensure that the producer sends records to the
appropriate cluster node for each partitioning key. For example, a Java-based client application should contain a producer
definition similar to the following to disable idempotency and configure the partitioning scheme:
Properties props = new Properties();
props.put("bootstrap.servers", "myvoltdb:9092");
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, VoltDBKafkaPartitioner.class.getName());
props.put("enable.idempotence","false");
props.put("client.id","myConsumer");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props); To access the VoltDB partitioner for Kafka, be sure to include the VoltDB client library JAR file in your classpath when compiling and running your producer client.
Opaque topics are a special type of topic that do not receive any interpretation or modification by the database. If you want to create a topic that is not processed but simply flows through VoltDB from producers to consumers, you declare the topic as "opaque" in the configuration file, without either specifying a stored procedure for input or associating a stream or table with the topic for output.
<topic name="sysmsgs" opaque="true"/>Opaque topics allow you to use a single set of brokers for all your topics even if you only need to analyze and process certain data feeds. Because there is no interpretation, you cannot specify a stored procedure, stream, table, or format for the topic. However, there are a few properties specific to opaque topics you can use to control how the data are handled.
One important control is whether the opaque topics are partitioned or not. Partitioning the opaque topics improves
throughput by distributing processing across the cluster. However, you can only partition opaque topics that have a key.
To partition an opaque topic you set the opaque.partitioned property to
true:
<topic name="sysmsgs" opaque="true">
<property name="opaque.partitioned">true</property>
</topic>You can specify a retention policy for opaque topics, just like regular topics. In fact, opaque topics have one additional retention option. Since the content is not analyzed in any way, it can be compressed to save space while it is stored. By specifying the retention policy as "compact" with a time limit, the records are stored compressed until the time limit expires. For example, the following configuration compresses the opaque topic data then deletes it after two months:
<topic name="sysmsgs" opaque="true" retention="compact 2 mo">
<property name="opaque.partitioned">true</property>
</topic>